0x00 puppeteer vs selenium
Puppeteer是一个Node库,封装了Chrome DevTools协议来提供操控Chrome的API。
| 优点 | 缺点 | |
|---|---|---|
| Puppeteer | - 性能好,容易安装,yarn、npm一键安装。 - Chrome官方维护。 - 更好地支持Chrome浏览器。 - 直接使用evaluate函数,便可在页面上下文执行JS代码。 |
- 官方只维护nodejs版本。python版本1年多没人维护。 - 只支持Chrome浏览器。 |
| Selenium | - 适配多种浏览器。 - 多语言支持。 - 开发者社区活跃,用户多。 |
- 比puppeteer要慢。 - 不同环境需要安装不同的WebDriver |
比较两者的代码可以感觉:
- Puppeteer基于用户的角度,Selenium是基于开发者编程的角度。
- Puppeteer由于官方只支持Nodejs,并且基于用户视角,可能会难用一些。但熟悉了,就很直观。只要是用户可以在Chrome上的操作,都能使用Puppeteer来模拟。
使用请看Github上给的API文档:
https://github.com/GoogleChrome/puppeteer/blob/v2.0.0/docs/api.md#
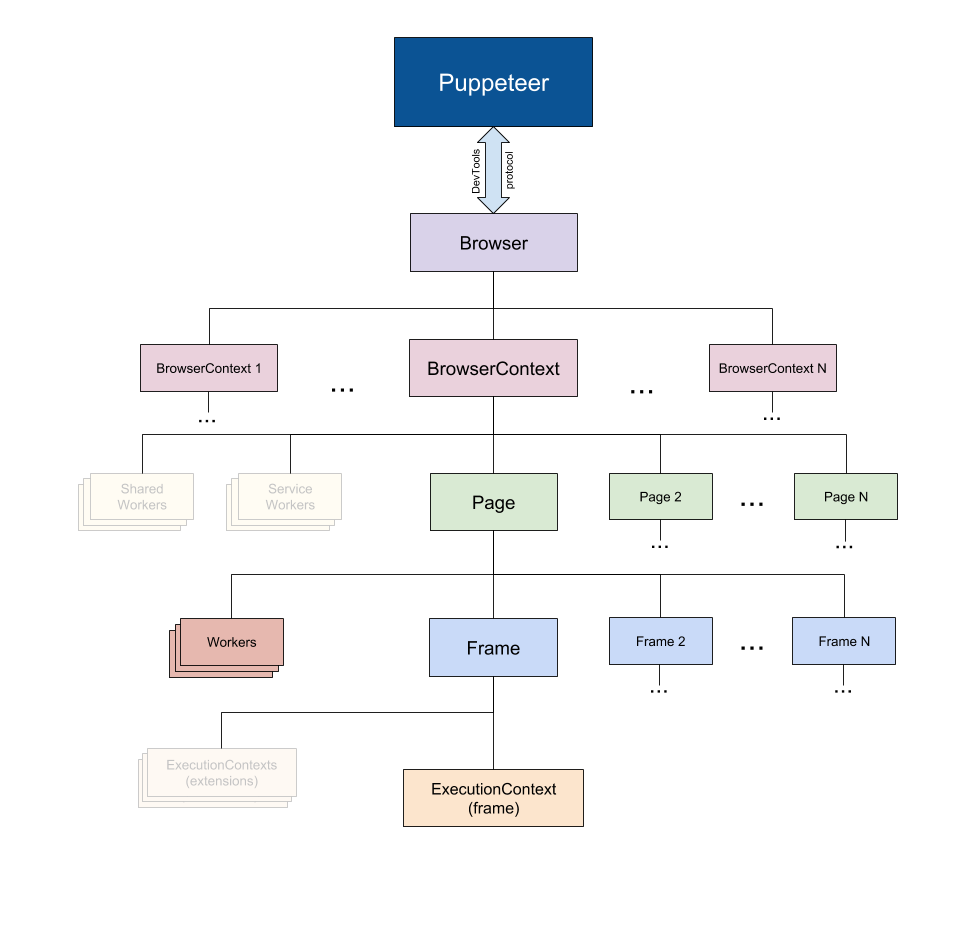
- Browser可以有多个BrowserContext。BrowserContext的Session互不干扰,默认情况下Browser生成单个BrowserContext。
- BrowserContext可以有多个Page,理解为浏览器的每个Tab。
- Page可以有多个Frame,和页面的frame一样,如:iframe,frame标签生成的。
0x01 使用记录和知识点
1. 安装
基于Node框架,直接yarn安装,会自动下载Chromium(Chrome的开源版本)。
1 | yarn add puppeteer |
2. 异步
Puppeteer所有的操作都是异步的(JS早期表现为回调函数)。现在需要理解Promise,及其语法糖async await。
以HTTP请求为例:
1 | $xxx.regPic = (filename)=>{ |
HTTP请求最好使用axios库,支持Promise。使用Promise的resolve函数来抛出成功后的Data,放到then里面处理。reject函数处理异常的Data,放到catch里面处理。
使用该方法的代码为:
1 | let captcha_res = await $xxx.regPic(captcha_filename); |
这里使用了await语法糖,当regPic函数执行成功时,会返回res.data赋值给captcha_res变量。相当于:
1 | $xxx.regPic(captcha_filename).then(res => { |
async语法糖作为一个关键字放在函数的前面,表示函数是一个异步函数。意味着被修饰的函数不会阻塞后面代码的执行。而async修饰的函数返回是1个promise对象。
3. 截图
可以实现页面长截屏效果,还可以模拟不同尺寸的设备:
1 | const puppeteer = require('puppeteer'); |
对部分元素截图(截取验证码):
1 | let captcha_filename = './captcha_images/' + '1.jpg'; |
4. 自动填充输入框
使用page的type方法填充输入框:
1 | await page.type('#Doctor_Name', testName); |
使用select方法选择单选框(填充值为option的value属性):
1 | await page.select('#Prov', prov_code); // 填入省份~ |
5. 清空输入框数据
跑多条数据时,需要清空前面写进去的数据。没有直接的clear方法,这里需要用到evaluate函数,无缝直接在页面环境下执行JS代码:
1 | await page.evaluate(() => { // clear input~ |
6. 自动点击
推荐使用$eval方法直接选择元素并点击:
1 | await page.$eval('#fm1 > div > div.col-lg-7.col-md-7.col-sm-6 > div:nth-child(5) > div > button', el => el.click()); |
7. 页面等待
由于是异步操作,时刻要小心页面渲染不及时的问题。
- 点击之后,建议sleep 500毫秒。
- 点击超链接到新的窗口,一定要先sleep 500毫秒。
1 | await page.waitFor(500); // 等待500毫秒 |
8. 页面切换
浏览器每个Tab都是一个page对象。直接获取所有的page对象,直接选取对应的page进行操作。
1 | await page.waitFor(500); // important,wait a mininute~ |
9. 获取页面元素内容
使用$eval函数获取:
1 | let name = await page_detail.$eval('body > div*****', el => el.innerText); |
10. Cookie操作
有setCookie和deleteCookie函数:
1 | await page.deleteCookie({name: "cookie_name"}); // 删除key为'cookie_name'的Cookie~ |
0x02 参考
Selenium 的使用
https://thief.one/2018/03/06/1/
https://github.com/dhamaniasad/HeadlessBrowsers
https://pypi.org/project/pyppeteer/
https://github.com/GoogleChrome/puppeteer
Selenium vs. Puppeteer for Test Automation: Is a New Leader Emerging?
Puppeteer vs Selenium